Recommendation Systems
There are many ways to recommend items to users. There are two primary types of recommendation systems, each with different sub-types. The two primary types are content-based and collaborative filtering.
Collaborative Filtering
It primarily makes recommendations based on inputs or actions from other people.
Ignore User and Item Attributes
Focus on User-Item Interactions
Pure Behavior-Based Recommendation
Variations on this type of recommendation system include:
Key Concepts
Nearest Neighbor Collaborative Filtering
User-User CF Algorithm
Neighborhoods and Tuning Parameters
Alternatives to Historic Agreement (social, trust)
Item-Item CF Algorithm
Dealing with Unary Data
Hybrids and Extensions
Practical Implications
User-User Collaborative Filtering
This strategy involves creating user groups by comparing users’ activities and providing recommendations that are popular among other members of the group. It is useful on sites with a strong but versatile audience to quickly provide recommendations for a user on which little information is available.
Find users similar to you and recommend what they like.
Excerise: Movie Recommendations
This is a 25 user x 100 movie matrix of ratings selected from the class data set. Rows are movies ratings, columns are users, and cells are ratings from 1 to 5.
import pandas as pd
import torch
import seaborn
import numpy as np
from sklearn.metrics.pairwise import cosine_similarity
df = pd.read_csv('https://github.com/akkefa/ml-notes/releases/download/v0.1.0/recommendation_systems_movies_ratings_data.csv')
df.head()
| Unnamed: 0 | 1648 | 5136 | 918 | 2824 | 3867 | 860 | 3712 | 2968 | 3525 | ... | 3556 | 5261 | 2492 | 5062 | 2486 | 4942 | 2267 | 4809 | 3853 | 2288 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 11: Star Wars: Episode IV - A New Hope (1977) | NaN | 4.5 | 5.0 | 4.5 | 4.0 | 4.0 | NaN | 5.0 | 4.0 | ... | 4.0 | NaN | 4.5 | 4.0 | 3.5 | NaN | NaN | NaN | NaN | NaN |
| 1 | 12: Finding Nemo (2003) | NaN | 5.0 | 5.0 | NaN | 4.0 | 4.0 | 4.5 | 4.5 | 4.0 | ... | 4.0 | NaN | 3.5 | 4.0 | 2.0 | 3.5 | NaN | NaN | NaN | 3.5 |
| 2 | 13: Forrest Gump (1994) | NaN | 5.0 | 4.5 | 5.0 | 4.5 | 4.5 | NaN | 5.0 | 4.5 | ... | 4.0 | 5.0 | 3.5 | 4.5 | 4.5 | 4.0 | 3.5 | 4.5 | 3.5 | 3.5 |
| 3 | 14: American Beauty (1999) | NaN | 4.0 | NaN | NaN | NaN | NaN | 4.5 | 2.0 | 3.5 | ... | 4.0 | NaN | 3.5 | 4.5 | 3.5 | 4.0 | NaN | 3.5 | NaN | NaN |
| 4 | 22: Pirates of the Caribbean: The Curse of the... | 4.0 | 5.0 | 3.0 | 4.5 | 4.0 | 2.5 | NaN | 5.0 | 3.0 | ... | 3.0 | 1.5 | 4.0 | 4.0 | 2.5 | 3.5 | NaN | 5.0 | NaN | 3.5 |
5 rows × 26 columns
tmp_df = df.copy()
# Drop the first column (movie title)
tmp_df.drop(columns=tmp_df.columns[0], axis=1, inplace=True)
tmp_df.head()
| 1648 | 5136 | 918 | 2824 | 3867 | 860 | 3712 | 2968 | 3525 | 4323 | ... | 3556 | 5261 | 2492 | 5062 | 2486 | 4942 | 2267 | 4809 | 3853 | 2288 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | NaN | 4.5 | 5.0 | 4.5 | 4.0 | 4.0 | NaN | 5.0 | 4.0 | 5.0 | ... | 4.0 | NaN | 4.5 | 4.0 | 3.5 | NaN | NaN | NaN | NaN | NaN |
| 1 | NaN | 5.0 | 5.0 | NaN | 4.0 | 4.0 | 4.5 | 4.5 | 4.0 | 5.0 | ... | 4.0 | NaN | 3.5 | 4.0 | 2.0 | 3.5 | NaN | NaN | NaN | 3.5 |
| 2 | NaN | 5.0 | 4.5 | 5.0 | 4.5 | 4.5 | NaN | 5.0 | 4.5 | 5.0 | ... | 4.0 | 5.0 | 3.5 | 4.5 | 4.5 | 4.0 | 3.5 | 4.5 | 3.5 | 3.5 |
| 3 | NaN | 4.0 | NaN | NaN | NaN | NaN | 4.5 | 2.0 | 3.5 | 5.0 | ... | 4.0 | NaN | 3.5 | 4.5 | 3.5 | 4.0 | NaN | 3.5 | NaN | NaN |
| 4 | 4.0 | 5.0 | 3.0 | 4.5 | 4.0 | 2.5 | NaN | 5.0 | 3.0 | 4.0 | ... | 3.0 | 1.5 | 4.0 | 4.0 | 2.5 | 3.5 | NaN | 5.0 | NaN | 3.5 |
5 rows × 25 columns
Given a set of items \(I\), and a set of users \(U\), and a sparse matrix of ratings \(R\), We compute the prediction \(s(\mathrm{u}, \mathrm{i})\) as follows:
For all users \(v \neq u\), compute \(w_{u v}\)
similarity metric (e.g., Pearson correlation)
Select a neighborhood of users \(V \subset U\) with highest \(w_{u v}\)
may limit neighborhood to top-k neighbors
may limit neighborhood to sim > sim_threshold
may use sim or |sim| (risks of negative correlations)
may limit neighborhood to people who rated i (if single-use)
Computing the person correlation coefficient between each pair of users. Pearson correlation coefficient formula:
where \(\bar{x}\) and \(\bar{y}\) are the means of \(x\) and \(y\) respectively.
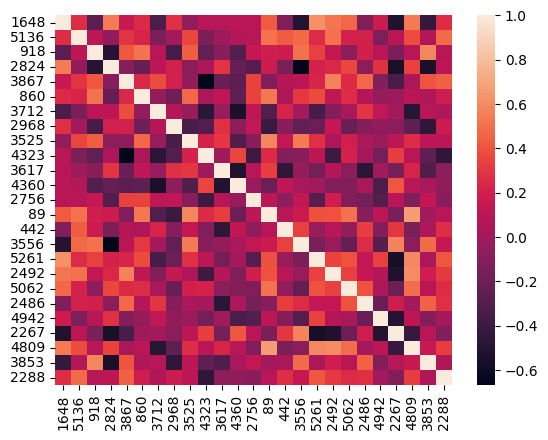
corr_df = tmp_df.corr()
corr_df
| 1648 | 5136 | 918 | 2824 | 3867 | 860 | 3712 | 2968 | 3525 | 4323 | ... | 3556 | 5261 | 2492 | 5062 | 2486 | 4942 | 2267 | 4809 | 3853 | 2288 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1648 | 1.000000 | 0.402980 | -0.142206 | 0.517620 | 0.300200 | 0.480537 | -0.312412 | 0.383348 | 0.092775 | 0.098191 | ... | -0.191988 | 0.493008 | 0.360644 | 0.551089 | 0.002544 | 0.116653 | -0.429183 | 0.394371 | -0.304422 | 0.245048 |
| 5136 | 0.402980 | 1.000000 | 0.118979 | 0.057916 | 0.341734 | 0.241377 | 0.131398 | 0.206695 | 0.360056 | 0.033642 | ... | 0.488607 | 0.328120 | 0.422236 | 0.226635 | 0.305803 | 0.037769 | 0.240728 | 0.411676 | 0.189234 | 0.390067 |
| 918 | -0.142206 | 0.118979 | 1.000000 | -0.317063 | 0.294558 | 0.468333 | 0.092037 | -0.045854 | 0.367568 | -0.035394 | ... | 0.373226 | 0.470972 | 0.069956 | -0.054762 | 0.133812 | 0.015169 | -0.273096 | 0.082528 | 0.667168 | 0.119162 |
| 2824 | 0.517620 | 0.057916 | -0.317063 | 1.000000 | -0.060913 | -0.008066 | 0.462910 | 0.214760 | 0.169907 | 0.119350 | ... | -0.201275 | 0.228341 | 0.238700 | 0.259660 | 0.247097 | 0.149247 | -0.361466 | 0.474974 | -0.262073 | 0.166999 |
| 3867 | 0.300200 | 0.341734 | 0.294558 | -0.060913 | 1.000000 | 0.282497 | 0.400275 | 0.264249 | 0.125193 | -0.333602 | ... | 0.174085 | 0.297977 | 0.476683 | 0.293868 | 0.438992 | -0.162818 | -0.295966 | 0.054518 | 0.464110 | 0.379856 |
| 860 | 0.480537 | 0.241377 | 0.468333 | -0.008066 | 0.282497 | 1.000000 | 0.171151 | 0.072927 | 0.387133 | 0.146158 | ... | 0.347470 | 0.399436 | 0.207314 | 0.311363 | 0.276306 | 0.079698 | 0.212991 | 0.165608 | 0.162314 | 0.279677 |
| 3712 | -0.312412 | 0.131398 | 0.092037 | 0.462910 | 0.400275 | 0.171151 | 1.000000 | 0.065015 | 0.095623 | -0.292501 | ... | 0.016406 | -0.240764 | -0.115254 | 0.247693 | 0.166913 | 0.146011 | 0.009685 | -0.451625 | 0.193660 | 0.113266 |
| 2968 | 0.383348 | 0.206695 | -0.045854 | 0.214760 | 0.264249 | 0.072927 | 0.065015 | 1.000000 | 0.028529 | -0.073252 | ... | 0.049132 | -0.009041 | 0.203613 | 0.033301 | 0.137982 | 0.070602 | 0.109452 | -0.083562 | -0.089317 | 0.229219 |
| 3525 | 0.092775 | 0.360056 | 0.367568 | 0.169907 | 0.125193 | 0.387133 | 0.095623 | 0.028529 | 1.000000 | 0.210879 | ... | 0.475711 | 0.306957 | 0.136343 | 0.301750 | 0.143414 | 0.056100 | 0.179908 | 0.284648 | 0.170757 | 0.193131 |
| 4323 | 0.098191 | 0.033642 | -0.035394 | 0.119350 | -0.333602 | 0.146158 | -0.292501 | -0.073252 | 0.210879 | 1.000000 | ... | -0.040606 | 0.155045 | -0.204164 | 0.263654 | 0.167198 | -0.084592 | 0.315712 | 0.085673 | -0.109892 | -0.279385 |
| 3617 | -0.041734 | 0.138548 | 0.011316 | 0.282756 | -0.066576 | 0.219929 | -0.038900 | 0.312573 | 0.243283 | 0.022907 | ... | 0.079571 | -0.165628 | 0.053306 | 0.007810 | -0.244637 | -0.030709 | -0.070660 | 0.268595 | -0.143503 | 0.013284 |
| 4360 | 0.264425 | 0.152948 | -0.231660 | -0.005326 | -0.093801 | -0.005316 | -0.364324 | 0.053024 | -0.086061 | 0.252529 | ... | 0.072993 | 0.161882 | -0.000311 | -0.077598 | 0.039389 | -0.156091 | 0.408592 | 0.179652 | 0.280402 | 0.040328 |
| 2756 | 0.261268 | 0.148882 | 0.148431 | -0.087747 | 0.310104 | 0.323499 | 0.126899 | 0.143347 | 0.058365 | -0.221789 | ... | 0.101784 | -0.140953 | 0.150476 | 0.024572 | -0.031130 | -0.133768 | 0.142067 | 0.015140 | 0.181210 | -0.005935 |
| 89 | 0.464610 | 0.562449 | 0.267029 | 0.241567 | -0.003878 | 0.539066 | -0.051320 | -0.118085 | 0.475495 | 0.258866 | ... | 0.326774 | 0.291476 | 0.372676 | 0.525990 | 0.123380 | 0.178088 | 0.088600 | 0.668516 | 0.179680 | 0.155869 |
| 442 | 0.022308 | 0.414438 | 0.304139 | 0.116532 | 0.113581 | 0.181276 | 0.227130 | 0.100841 | 0.201734 | -0.024337 | ... | 0.251660 | 0.046822 | 0.218575 | 0.150431 | 0.280392 | 0.038378 | 0.262520 | 0.064179 | -0.023439 | 0.257864 |
| 3556 | -0.191988 | 0.488607 | 0.373226 | -0.201275 | 0.174085 | 0.347470 | 0.016406 | 0.049132 | 0.475711 | -0.040606 | ... | 1.000000 | 0.086665 | 0.158739 | -0.016164 | 0.256537 | -0.055137 | 0.503247 | 0.100277 | 0.423225 | 0.222458 |
| 5261 | 0.493008 | 0.328120 | 0.470972 | 0.228341 | 0.297977 | 0.399436 | -0.240764 | -0.009041 | 0.306957 | 0.155045 | ... | 0.086665 | 1.000000 | 0.149165 | 0.372177 | 0.198086 | 0.270928 | -0.393376 | 0.455274 | 0.039050 | 0.374264 |
| 2492 | 0.360644 | 0.422236 | 0.069956 | 0.238700 | 0.476683 | 0.207314 | -0.115254 | 0.203613 | 0.136343 | -0.204164 | ... | 0.158739 | 0.149165 | 1.000000 | 0.276883 | 0.158002 | 0.035825 | -0.345495 | 0.449025 | 0.289410 | 0.169239 |
| 5062 | 0.551089 | 0.226635 | -0.054762 | 0.259660 | 0.293868 | 0.311363 | 0.247693 | 0.033301 | 0.301750 | 0.263654 | ... | -0.016164 | 0.372177 | 0.276883 | 1.000000 | 0.403809 | 0.028521 | 0.107821 | 0.428055 | 0.407044 | 0.278868 |
| 2486 | 0.002544 | 0.305803 | 0.133812 | 0.247097 | 0.438992 | 0.276306 | 0.166913 | 0.137982 | 0.143414 | 0.167198 | ... | 0.256537 | 0.198086 | 0.158002 | 0.403809 | 1.000000 | -0.068421 | 0.173797 | 0.105761 | 0.472361 | 0.257462 |
| 4942 | 0.116653 | 0.037769 | 0.015169 | 0.149247 | -0.162818 | 0.079698 | 0.146011 | 0.070602 | 0.056100 | -0.084592 | ... | -0.055137 | 0.270928 | 0.035825 | 0.028521 | -0.068421 | 1.000000 | -0.346386 | -0.004638 | 0.143672 | 0.074476 |
| 2267 | -0.429183 | 0.240728 | -0.273096 | -0.361466 | -0.295966 | 0.212991 | 0.009685 | 0.109452 | 0.179908 | 0.315712 | ... | 0.503247 | -0.393376 | -0.345495 | 0.107821 | 0.173797 | -0.346386 | 1.000000 | -0.339845 | 0.165960 | 0.156341 |
| 4809 | 0.394371 | 0.411676 | 0.082528 | 0.474974 | 0.054518 | 0.165608 | -0.451625 | -0.083562 | 0.284648 | 0.085673 | ... | 0.100277 | 0.455274 | 0.449025 | 0.428055 | 0.105761 | -0.004638 | -0.339845 | 1.000000 | 0.542192 | 0.435520 |
| 3853 | -0.304422 | 0.189234 | 0.667168 | -0.262073 | 0.464110 | 0.162314 | 0.193660 | -0.089317 | 0.170757 | -0.109892 | ... | 0.423225 | 0.039050 | 0.289410 | 0.407044 | 0.472361 | 0.143672 | 0.165960 | 0.542192 | 1.000000 | 0.080403 |
| 2288 | 0.245048 | 0.390067 | 0.119162 | 0.166999 | 0.379856 | 0.279677 | 0.113266 | 0.229219 | 0.193131 | -0.279385 | ... | 0.222458 | 0.374264 | 0.169239 | 0.278868 | 0.257462 | 0.074476 | 0.156341 | 0.435520 | 0.080403 | 1.000000 |
25 rows × 25 columns
seaborn.heatmap(corr_df.corr())
<Axes: >
corr_df["3867"].sort_values(ascending=False)
3867 1.000000
2492 0.476683
3853 0.464110
2486 0.438992
3712 0.400275
2288 0.379856
5136 0.341734
2756 0.310104
1648 0.300200
5261 0.297977
918 0.294558
5062 0.293868
860 0.282497
2968 0.264249
3556 0.174085
3525 0.125193
442 0.113581
4809 0.054518
89 -0.003878
2824 -0.060913
3617 -0.066576
4360 -0.093801
4942 -0.162818
2267 -0.295966
4323 -0.333602
Name: 3867, dtype: float64
corr_df["89"].sort_values(ascending=False)
89 1.000000
4809 0.668516
5136 0.562449
860 0.539066
5062 0.525990
3525 0.475495
1648 0.464610
2492 0.372676
3556 0.326774
442 0.296826
5261 0.291476
2756 0.290591
3617 0.278335
918 0.267029
4323 0.258866
2824 0.241567
3853 0.179680
4942 0.178088
2288 0.155869
2486 0.123380
2267 0.088600
3867 -0.003878
3712 -0.051320
4360 -0.115492
2968 -0.118085
Name: 89, dtype: float64
Compute the predictions for each movie for users 3867 and 89 by taking the correlation-weighted average of the ratings of the top-five neighbors (for each target user) for each movie. The formal formula for correlation-weighted average is
where \(N\) is the set of the top-five neighbors of user \(u\) and \(x_{v,i}\) is the rating of user \(v\) for movie \(i\).
def get_top_users(df_corr,target,n=5):
target_cor = df_corr.loc[target]
top_neighbors = target_cor.nlargest(n+1).iloc[1:]
return top_neighbors
def get_user_movie_score(movie,user):
neighbors = get_top_users(corr_df,str(user))
rating_sum = 0
weight_sum = 0
for user,w in zip(neighbors.index,neighbors.values):
if np.isnan(movie[user]):
continue
rating_sum += movie[user] * w
weight_sum += w
if weight_sum == 0:
return 0
else:
return rating_sum/weight_sum
get_top_users(corr_df,"3867")
2492 0.476683
3853 0.464110
2486 0.438992
3712 0.400275
2288 0.379856
Name: 3867, dtype: float64
get_top_users(corr_df,"3712")
2824 0.462910
3867 0.400275
5062 0.247693
442 0.227130
3853 0.193660
Name: 3712, dtype: float64
pred_3867 = df.apply(get_user_movie_score,axis=1,args=(3867,))
pred_89 = df.apply(get_user_movie_score,axis=1,args=(89,))
pred_3867.sort_values(ascending=False)[:3]
77 4.760291
21 4.551454
16 4.507637
dtype: float64
for i in pred_3867.sort_values(ascending=False)[:5].index:
print(df.loc[i][0])
1891: Star Wars: Episode V - The Empire Strikes Back (1980)
155: The Dark Knight (2008)
122: The Lord of the Rings: The Return of the King (2003)
77: Memento (2000)
121: The Lord of the Rings: The Two Towers (2002)
/tmp/ipykernel_1076/879984262.py:2: FutureWarning: Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
print(df.loc[i][0])
for i in pred_89.sort_values(ascending=False)[:5].index:
print(df.loc[i][0])
238: The Godfather (1972)
278: The Shawshank Redemption (1994)
807: Seven (a.k.a. Se7en) (1995)
275: Fargo (1996)
424: Schindler's List (1993)
/tmp/ipykernel_1076/3855090423.py:2: FutureWarning: Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
print(df.loc[i][0])
Normalization
def get_norm_user_movie_score(movie,user):
user = str(user)
neighbors = get_top_users(corr_df,str(user))
rating_sum = 0
weight_sum = 0
user_rating_mean = df.loc[:,user].mean()
for user,w in zip(neighbors.index,neighbors.values):
if np.isnan(movie[user]):
continue
movie_user_mean = df.loc[:,user].mean()
rating_sum += (movie[user]-movie_user_mean) * w
weight_sum += w
if weight_sum == 0:
return 0
else:
return user_rating_mean + rating_sum/weight_sum
norm_pred_3867 = df.apply(get_norm_user_movie_score,axis=1,args=(3867,))
norm_pred_89 = df.apply(get_norm_user_movie_score,axis=1,args=(89,))
for i in norm_pred_3867.sort_values(ascending=False)[:5].index:
print(df.loc[i][0])
1891: Star Wars: Episode V - The Empire Strikes Back (1980)
155: The Dark Knight (2008)
77: Memento (2000)
275: Fargo (1996)
807: Seven (a.k.a. Se7en) (1995)
/tmp/ipykernel_1076/3753397190.py:2: FutureWarning: Series.__getitem__ treating keys as positions is deprecated. In a future version, integer keys will always be treated as labels (consistent with DataFrame behavior). To access a value by position, use `ser.iloc[pos]`
print(df.loc[i][0])
Problem in User - User Collaborative Filtering:
Issues of Sparsity – With large item sets, small numbers of ratings, too often there are points where no recommendation can be made (for a user, for an item to a set of users, etc.) – Many solutions proposed here, including “filterbots”, item‐item, and dimensionality reduction
Computational performance – With millions of users (or more), computing all‐ pairs correlations is expensive – Even incremental approaches were expensive – And user profiles could change quickly – needed to compute in real time to keep users happy
Item-Item Collaborative Filtering
Item‐Item similarity is fairly stable.
This is dependent on having many more usersthan items
Average item has many more ratings than an average user
Intuitively, items don’t generally change rapidly – at least not in ratings space (special case for time‐bound items)
Item similarity is a route to computing a prediction of a user’s item preference
https://github.com/shenweichen/Coursera/blob/master/Specialization_Recommender_System_University_of_Minnesota/Course2_Nearest_Neighbor_Collaborative_Filtering/Item%20Based%20Assignment.ipynb
data = pd.read_excel("https://github.com/akkefa/ml-notes/releases/download/v0.1.0/item_item_cb.xls", sheet_name=0)
data = data.fillna(0)
data.head()
| User | 1: Toy Story (1995) | 1210: Star Wars: Episode VI - Return of the Jedi (1983) | 356: Forrest Gump (1994) | 318: Shawshank Redemption, The (1994) | 593: Silence of the Lambs, The (1991) | 3578: Gladiator (2000) | 260: Star Wars: Episode IV - A New Hope (1977) | 2028: Saving Private Ryan (1998) | 296: Pulp Fiction (1994) | ... | 2916: Total Recall (1990) | 780: Independence Day (ID4) (1996) | 541: Blade Runner (1982) | 1265: Groundhog Day (1993) | 2571: Matrix, The (1999) | 527: Schindler's List (1993) | 2762: Sixth Sense, The (1999) | 1198: Raiders of the Lost Ark (1981) | 34: Babe (1995) | Mean | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 755 | 2.0 | 5.0 | 2.0 | 0.0 | 4.0 | 4.0 | 1.0 | 2.0 | 0.0 | ... | 0.0 | 5.0 | 2.0 | 5.0 | 4.0 | 2.0 | 5.0 | 0.0 | 0.0 | 3.200000 |
| 1 | 5277 | 1.0 | 0.0 | 0.0 | 2.0 | 4.0 | 2.0 | 5.0 | 0.0 | 0.0 | ... | 2.0 | 2.0 | 0.0 | 2.0 | 0.0 | 5.0 | 1.0 | 3.0 | 0.0 | 2.769231 |
| 2 | 1577 | 0.0 | 0.0 | 0.0 | 5.0 | 2.0 | 0.0 | 0.0 | 0.0 | 0.0 | ... | 1.0 | 4.0 | 4.0 | 1.0 | 1.0 | 2.0 | 3.0 | 1.0 | 3.0 | 2.333333 |
| 3 | 4388 | 2.0 | 3.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 3.0 | 4.0 | ... | 4.0 | 0.0 | 3.0 | 5.0 | 0.0 | 5.0 | 1.0 | 1.0 | 2.0 | 2.833333 |
| 4 | 1202 | 0.0 | 3.0 | 4.0 | 1.0 | 4.0 | 1.0 | 4.0 | 4.0 | 0.0 | ... | 1.0 | 0.0 | 4.0 | 0.0 | 3.0 | 5.0 | 5.0 | 0.0 | 0.0 | 3.214286 |
5 rows × 22 columns
matrix = pd.read_excel('https://github.com/akkefa/ml-notes/releases/download/v0.1.0/item_item_cb.xls',sheet_name=2)
matrix.head()
| Unnamed: 0 | 1: Toy Story (1995) | 1210: Star Wars: Episode VI - Return of the Jedi (1983) | 356: Forrest Gump (1994) | 318: Shawshank Redemption, The (1994) | 593: Silence of the Lambs, The (1991) | 3578: Gladiator (2000) | 260: Star Wars: Episode IV - A New Hope (1977) | 2028: Saving Private Ryan (1998) | 296: Pulp Fiction (1994) | ... | 2396: Shakespeare in Love (1998) | 2916: Total Recall (1990) | 780: Independence Day (ID4) (1996) | 541: Blade Runner (1982) | 1265: Groundhog Day (1993) | 2571: Matrix, The (1999) | 527: Schindler's List (1993) | 2762: Sixth Sense, The (1999) | 1198: Raiders of the Lost Ark (1981) | 34: Babe (1995) | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1: Toy Story (1995) | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 1 | 1210: Star Wars: Episode VI - Return of the Je... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 2 | 356: Forrest Gump (1994) | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 3 | 318: Shawshank Redemption, The (1994) | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
| 4 | 593: Silence of the Lambs, The (1991) | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN |
5 rows × 21 columns
matrix = pd.DataFrame(cosine_similarity(data.values[:-1,1:-1].T),index=matrix.index,columns=matrix.columns[1:])
matrix = matrix.applymap(lambda x:max(0,x))
/tmp/ipykernel_1076/1610576545.py:1: FutureWarning: DataFrame.applymap has been deprecated. Use DataFrame.map instead.
matrix = matrix.applymap(lambda x:max(0,x))
matrix.columns
Index(['1: Toy Story (1995)',
'1210: Star Wars: Episode VI - Return of the Jedi (1983)',
'356: Forrest Gump (1994)', '318: Shawshank Redemption, The (1994)',
'593: Silence of the Lambs, The (1991)', '3578: Gladiator (2000)',
'260: Star Wars: Episode IV - A New Hope (1977)',
'2028: Saving Private Ryan (1998)', '296: Pulp Fiction (1994)',
'1259: Stand by Me (1986)', '2396: Shakespeare in Love (1998)',
'2916: Total Recall (1990)', '780: Independence Day (ID4) (1996)',
'541: Blade Runner (1982)', '1265: Groundhog Day (1993)',
'2571: Matrix, The (1999)', '527: Schindler's List (1993)',
'2762: Sixth Sense, The (1999)', '1198: Raiders of the Lost Ark (1981)',
'34: Babe (1995)'],
dtype='object')
matrix.iloc[0].nlargest(6).iloc[1:]
260: Star Wars: Episode IV - A New Hope (1977) 0.747409
780: Independence Day (ID4) (1996) 0.690665
296: Pulp Fiction (1994) 0.667846
318: Shawshank Redemption, The (1994) 0.667424
1265: Groundhog Day (1993) 0.661016
Name: 0, dtype: float64
def get_score(row,user):
user_rating = data.loc[(data.User==user)]
user_hist_item = user_rating.columns[pd.notnull(user_rating).values[0]]
movie_name = row.name
neighbor_names = user_hist_item.tolist()#row.index.tolist()
if 'User' in neighbor_names:
neighbor_names.remove('User')
if 'Mean' in neighbor_names:
neighbor_names.remove('Mean')
a = row.loc[neighbor_names].values
b = data.loc[data.User==user,neighbor_names]
return np.dot(a,b.values[0])/np.sum(a)
user_rating = data.loc[data.User==5277]
idx = user_rating.columns[pd.notnull(user_rating).values[0]].tolist()
idx.remove('User')
idx.remove('Mean')
idx
['1: Toy Story (1995)',
'1210: Star Wars: Episode VI - Return of the Jedi (1983)',
'356: Forrest Gump (1994)',
'318: Shawshank Redemption, The (1994)',
'593: Silence of the Lambs, The (1991)',
'3578: Gladiator (2000)',
'260: Star Wars: Episode IV - A New Hope (1977)',
'2028: Saving Private Ryan (1998)',
'296: Pulp Fiction (1994)',
'1259: Stand by Me (1986)',
'2396: Shakespeare in Love (1998)',
'2916: Total Recall (1990)',
'780: Independence Day (ID4) (1996)',
'541: Blade Runner (1982)',
'1265: Groundhog Day (1993)',
'2571: Matrix, The (1999)',
"527: Schindler's List (1993)",
'2762: Sixth Sense, The (1999)',
'1198: Raiders of the Lost Ark (1981)',
'34: Babe (1995)']
ans = matrix.apply(get_score,axis=1,args=(5277,))