Hypothesis Testing
Statistical inference is the process of learning about characteristics of a population based on what is observed in a relatively small sample from that population. A sample will never give us the entire picture though, and we are bound to make incorrect decisions from time to time.
We will learn how to derive and interpret appropriate tests to manage this error and how to evaluate when one test is better than another. we will learn how to construct and perform principled hypothesis tests for a wide range of problems and applications when they are not.
What is Hypothesis
Hypothesis testing is an act in statistics whereby an analyst tests an assumption regarding a population parameter.
Hypothesis testing is a formal procedure for investigating our ideas about the world using statistics. It is most often used by scientists to test specific predictions, called hypotheses, that arise from theories.
Note
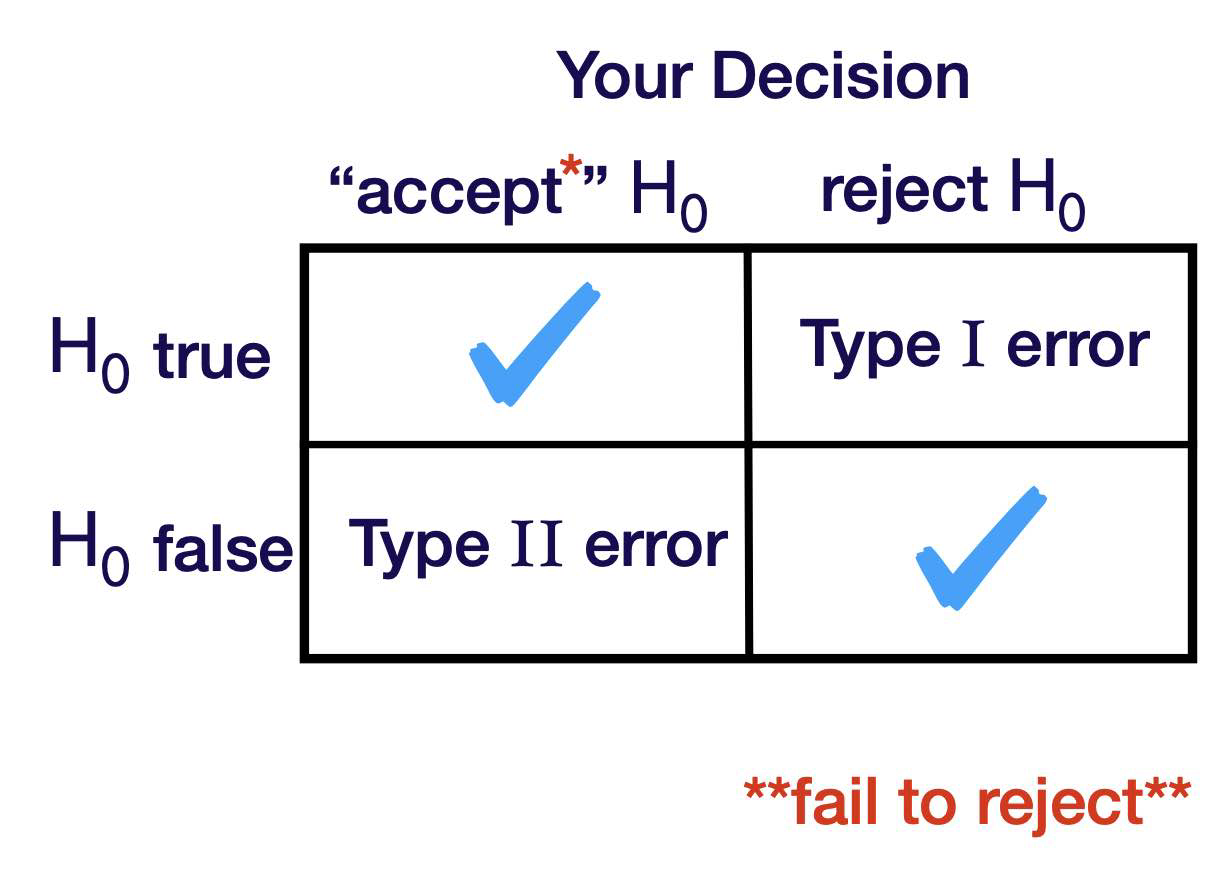
Due to random samples and randomness in the problem, we can different errors in our hypothesis testing. These errors are called Type I and Type II errors.
Type of hypothesis testing
Let \(X_1, X_2, \ldots, X_n\) be a random sample from the normal distribution with mean \(\mu\) and variance \(\sigma^2\)
import torch
import matplotlib.pyplot as plt
import seaborn as sns
from scipy.stats import norm
sns.set_theme(style="darkgrid")
sample = torch.normal(mean = 0, std = 1, size=(1,1000))
sns.displot(sample[0], kde=True, stat = 'density',)
plt.axvline(torch.mean(sample[0]), color='red', label='mean')
plt.show()

Example of random sample after it is observed:
Based on what you are seeing, do you believe that the true population mean \(\mu\) is
This is below 3 , but can we say that \(\mu<3\) ?
This seems awfully dependent on the random sample we happened to get! Let’s try to work with the most generic random sample of size 8:
Let \(\mathrm{X}_1, \mathrm{X}_2, \ldots, \mathrm{X}_{\mathrm{n}}\) be a random sample of size \(\mathrm{n}\) from the \(\mathrm{N}\left(\mu, \sigma^2\right)\) distribution.
The Sample mean is
We’re going to tend to think that \(\mu<3\) when \(\bar{X}\) is “significantly” smaller than 3.
We’re going to tend to think that \(\mu>3\) when \(\bar{X}\) is “significantly” larger than 3.
We’re never going to observe \(\bar{X}=3\), but we may be able to be convinced that \(\mu=3\) if \(\bar{X}\) is not too far away.
How do we formalize this stuff, We use hypothesis testing
Notation
\(\mathrm{H}_0: \mu \leq 3\) <- Null hypothesis
\(\mathrm{H}_1: \mu>3 \quad\) Alternate hypothesis
Null hypothesis
The null hypothesis is a hypothesis that is assumed to be true. We denote it with an \(H_0\).
Alternate hypothesis
The alternate hypothesis is what we are out to show. The alternative hypothesis is a hypothesis that we are looking for evidence for or out to show. We denote it with an \(H_1\).
Note
Some people use the notation \(H_a\) here
Conclusion is either:
Reject \(\mathrm{H}_0 \quad\) OR \(\quad\) Fail to Reject \(\mathrm{H}_0\)
simple hypothesis
A simple hypothesis is one that completely specifies the distribution. Do you know the exact distribution.
composite hypothesis
You don’t know the exact distribution.
Means you know the distribution is normal but you don’t know the mean and variance.
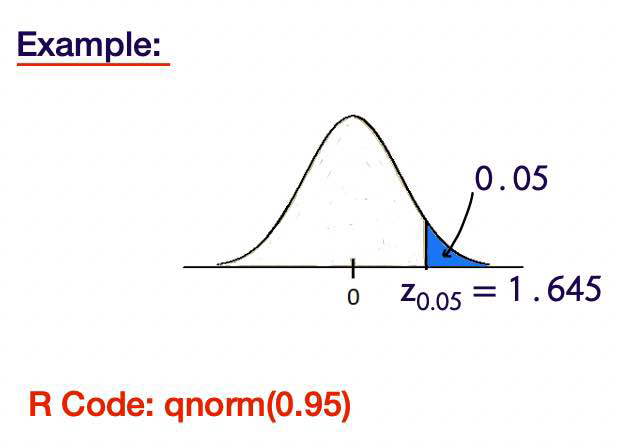
Critical values
Critical values for distributions are numbers that cut off specified areas under pdfs. For the N(0, 1) distribution, we will use the notation \(z_\alpha\) to denote the value that cuts off area \(\alpha\) to the right as depicted here.

Errors in Hypothesis Testing
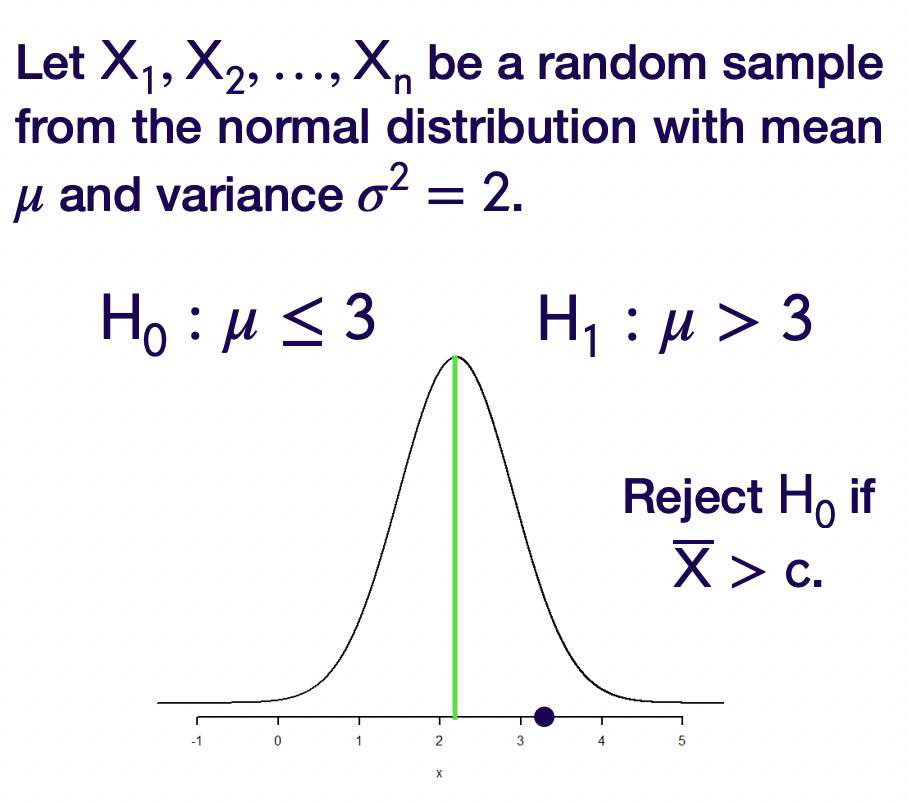
Let \(X_1, X_2, \ldots, X_n\) be a random sample from the normal distribution with mean \(\mu\) and variance \(\sigma^2=2\)
Idea: Look at \(\bar{X}\) and reject \(H_0\) in favor of \(H _1\) if \(\overline{ X }\) is “large”.
i.e. Look at \(\bar{X}\) and reject \(H_0\) in favor of \(H _1\) if \(\overline{ X }> c\) for some value \(c\).
You are a potato chip manufacturer and you want to ensure that the mean amount in 15 ounce bags is at least 15 ounces. \(\mathrm{H}_0: \mu \leq 15 \quad \mathrm{H}_1: \mu>15\)
Type I Error
The true mean is \(\leq 15\) but you concluded i was \(>15\). You are going to save some money because you won’t be adding chips but you are risking a lawsuit!
Type II Error
The true mean is \(> 15\) but you concluded it was \(\leq 15\) . You are going to be spending money increasing the amount of chips when you didn’t have to.
Developing a Test
Let \(X_1, X_2, \ldots, X_n\) be a random sample from the normal distribution with mean \(\mu\) and known variance \(\sigma^2\).
Consider testing the simple versus simple hypotheses
level of significance
Let \(\alpha= P\) (Type I Error)
\(= P \left(\right.\) Reject \(H _0\) when it’s true \()\)
\(= P \left(\right.\) Reject \(H _0\) when \(\left.\mu=5\right)\)
\(\alpha\) is called the level of significance of the test. It is also sometimes referred to as the size of the test.
Power of the test
\(1-\beta\) is known as the power of the test
Step One
Choose an estimator for μ.
Step Two
Choose a test statistic or Give the “form” of the test.
We are looking for evidence that \(H _1\) is true.
The \(N \left(3, \sigma^2\right)\) distribution takes on values from \(-\infty\) to \(\infty\).
\(\overline{ X } \sim N \left(\mu, \sigma^2 / n \right) \Rightarrow \overline{ X }\) also takes on values from \(-\infty\) to \(\infty\).
It is entirely possible that \(\bar{X}\) is very large even if the mean of its distribution is 3.
However, if \(\bar{X}\) is very large, it will start to seem more likely that \(\mu\) is larger than 3.
Eventually, a population mean of 5 will seem more likely than a population mean of 3.
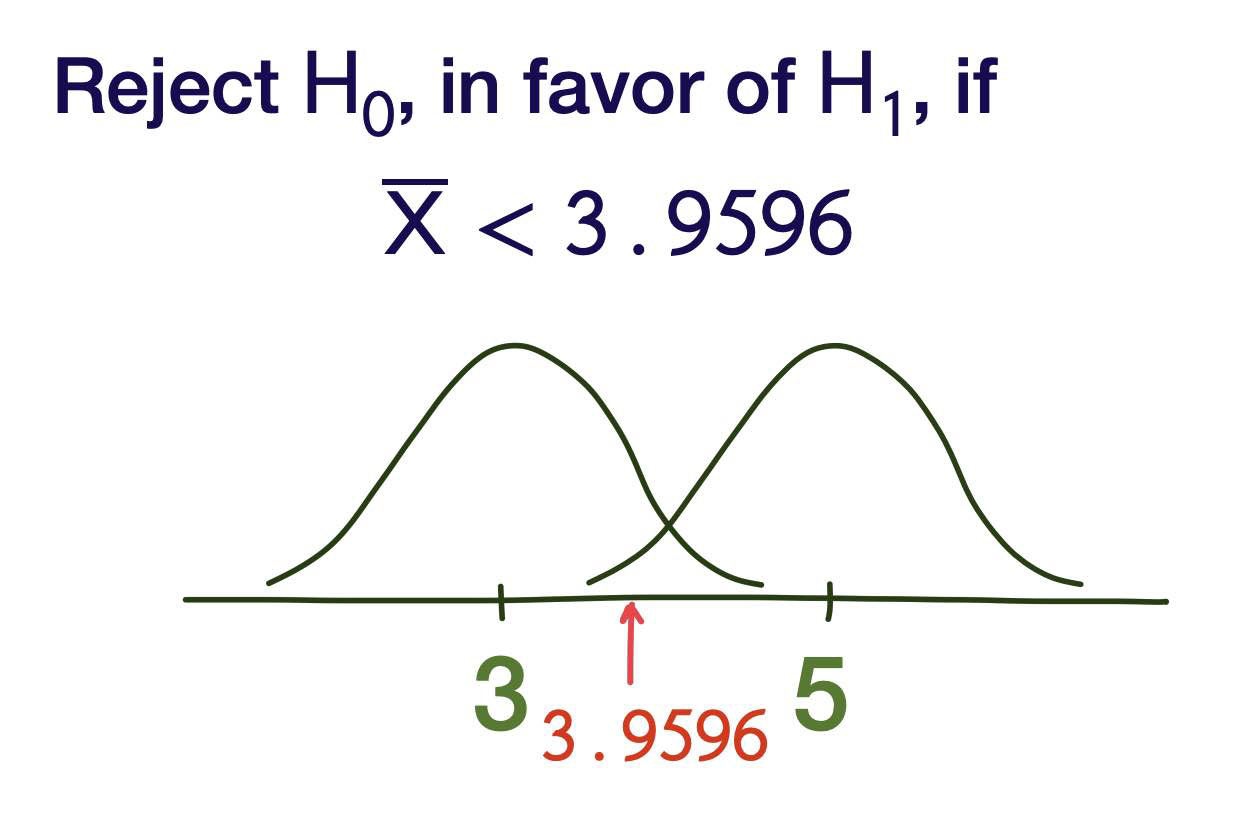
Reject \(H _0\), in favor of \(H _1\), if \(\overline{ X }< c\) for some c to be determined.
Step Three
Find c.
If \(c\) is too large, we are making it difficult to reject \(H _0\). We are more likely to fail to reject when it should be rejected.
If \(c\) is too small, we are making it to easy to reject \(H _0\). We are more likely reject when it should not be rejected.
This is where \(\alpha\) comes in.
Step Four
Give a conclusion!
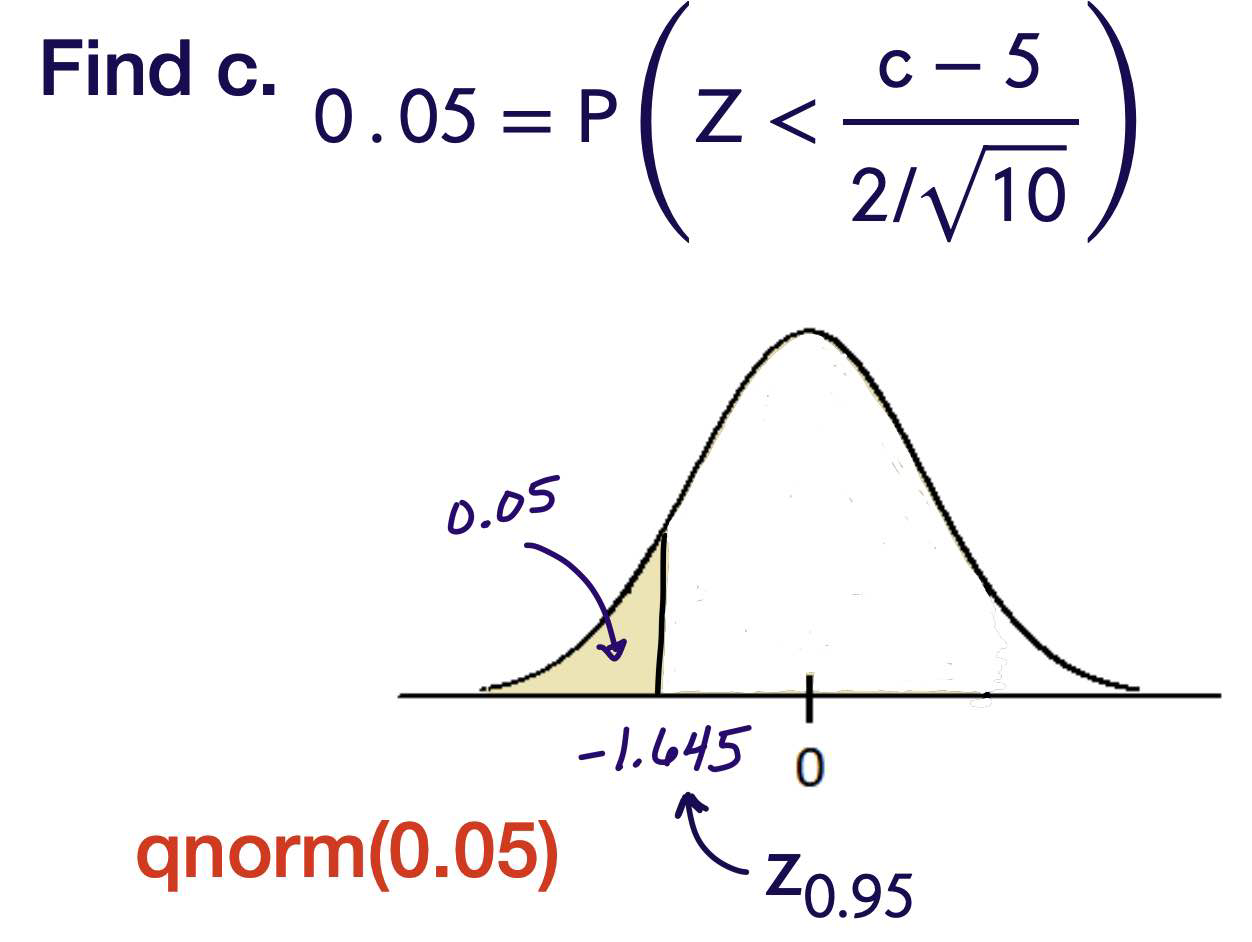
\(0.05= P (\) Type I Error)
\(= P \left(\right.\) Reject \(H _0\) when true \()\)
\(= P (\overline{ X }< \text{ c when } \mu=5)\)
\( = P \left(\frac{\overline{ X }-\mu_0}{\sigma / \sqrt{ n }}<\frac{ c -5}{2 / \sqrt{10}}\right.\) when \(\left.\mu=5\right)\)
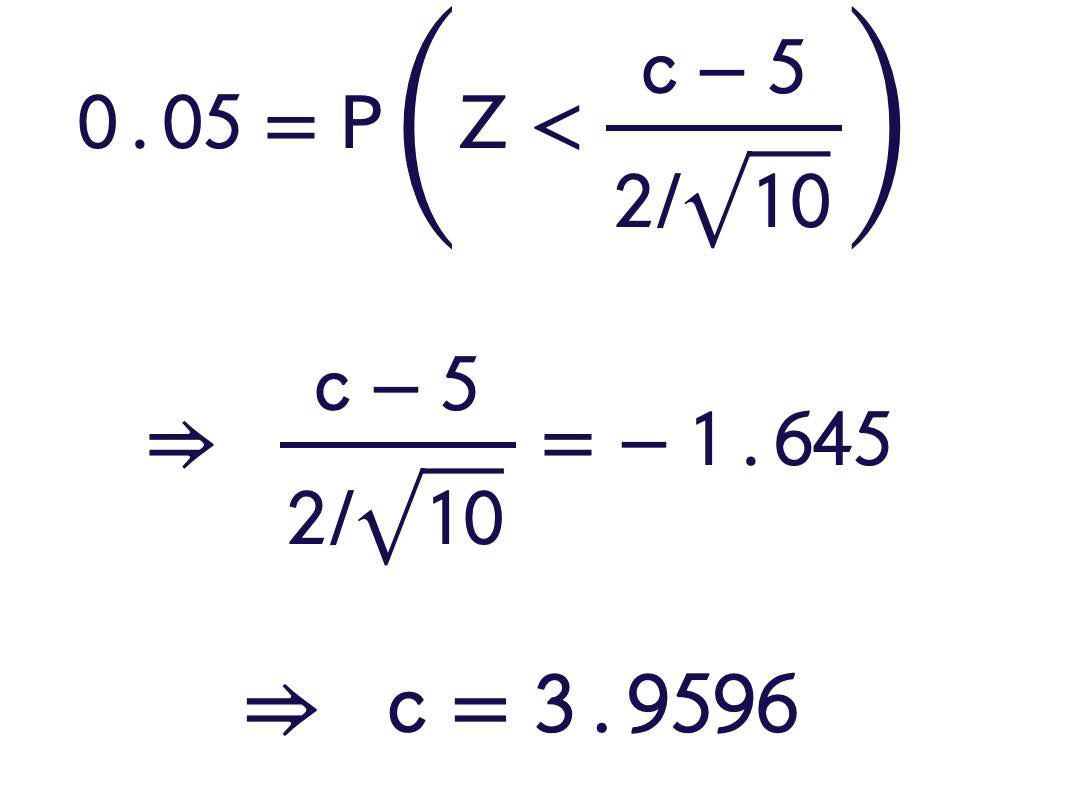
Formula
Let \(X_1, X_2, \ldots, X_n\) be a random sample from the normal distribution with mean \(\mu\) and known variance \(\sigma^2\).
Consider testing the simple versus simple hypotheses
where \(\mu_0\) and \(\mu_1\) are fixed and known.
Type II Error
Composite vs Composite Hypothesis
Step One Choose an estimator for μ
Step Two Choose a test statistic: Reject \(H_0\) , in favor of \(H_1\) if \(\bar{𝖷}\) > c, where c is to be determined.
Step Three Find c.
One-Tailed Tests
Let \(X_1, X_2, \ldots, X_n\) be a random sample from the normal distribution with mean \(\mu\) and known variance \(\sigma^2\). Consider testing the hypotheses
where \(\mu_0\) is fixed and known.
Step One
Choose an estimator for μ.
Step Two
Choose a test statistic or Give the “form” of the test.
Reject \(H _0\), in favor of \(H _1\), if \(\overline{ X }< c\) for some c to be determined.
Step Three
Find c.
Step four
Reject \(H _0\), in favor of \(H _1\), if $\( \overline{ X }<\mu_0+ z _{1-\alpha} \frac{\sigma}{\sqrt{ n }} \)$
Example
In 2019, the average health care annual premium for a family of 4 in the United States, was reported to be \(\$ 6,015\).
In a more recent survey, 100 randomly sampled families of 4 reported an average annual health care premium of \(\$ 6,537\). Can we say that the true average is currently greater than \(\$ 6,015\) for all families of 4?
Assume that annual health care premiums are normally distributed with a standard deviation of \(\$ 814\). Let \(\mu\) be the true average for all families of 4.
Step Zero
Set up the hypotheses.
Decide on a level of significance. \( \alpha=0.10\)
Step One
Choose an estimator for \(\mu\).
Step Two
Give the form of the test. Reject \(H _0\), in favor of \(H _1\), if
for some \(c\) to be determined.
Step Three
Find c.
Step Four
Conclusion. Reject \(H _0\), in favor of \(H _1\), if
From the data, where \(\bar{x}=6537\), we reject \(H _0\) in favor of \(H _1\).
The data suggests that the true mean annual health care premium is greater than \(\$ 6015\).
Hypothesis Testing with P-Values
Recall that p-values are defined as the following: A p-value is the probability that we observe a test statistic at least as extreme as the one we calculated, assuming the null hypothesis is true. It isn’t immediately obvious what that definition means, so let’s look at some examples to really get an idea of what p-values are, and how they work.
Let’s start very simple and say we have 5 data points: x = <1, 2, 3, 4, 5>. Let’s also assume the data were generated from some normal distribution with a known variance \(\sigma\) but an unknown mean \(\mu_0\). What would be a good guess for the true mean? We know that this data could come from any normal distribution, so let’s make two wild guesses:
The true mean is 100.
The true mean is 3.
Intuitively, we know that 3 is the better guess. But how do we actually determine which of these guesses is more likely? By looking at the data and asking “how likely was the data to occur, assuming the guess is true?”
What is the probability that we observed x=<1,2,3,4,5> assuming the mean is 100? Probabiliy pretty low. And because the p-value is low, we “reject the null hypothesis” that \(\mu_0 = 100\).
What is the probability that we observed x=<1,2,3,4,5> assuming the mean is 3? Seems reasonable. However, something to be careful of is that p-values do not prove anything. Just because it is probable for the true mean to be 3, does not mean we know the true mean is 3. If we have a high p-value, we “fail to reject the null hypothesis” that \(\mu_0 = 3\).
What do “low” and “high” mean? That is where your significance level \(\alpha\) comes back into play. We consider a p-value low if the p-value is less than \(\alpha\), and high if it is greater than \(\alpha\).
Example
From the above example.


This is the \(N\left(6015,814^2 / 100\right)\) pdf.
The red area is \(P (\overline{ X }>6537)\).
The P-Value is the area to the right (in this case) of the test statistic \(\bar{X}\).
The P-value being less than \(0.10\) puts \(\bar{X}\) in the rejection region.
The P-value is also less than \(0.05\) and \(0.01\).
It looks like we will reject \(H _0\) for the most typical values of \(\alpha\).
Power Functions
Let \(X_1, X_2, \ldots, X_n\) be a random sample from any distribution with unknown parameter \(\theta\) which takes values in a parameter space \(\Theta\)
We ultimately want to test
where \(\Theta_0\) is some subset of \(\Theta\).
So in other words, if the null hypothesis was for you to test for an exponential distribution, whether lambda was between 0 and 2, the complement of that is not the rest of the real number line because the space is only non-negative values. So the complement of the interval from 0 to 2 in that space is 2 to infinity.
\(\gamma(\theta)= P \left(\right.\) Reject \(H _0\) when the parameter is \(\left.\theta\right)\)
\(\theta\) is an argument that can be anywhere in the parameter space \(\Theta\). it could be a \(\theta\) from \(H _0\) it could be a \(\theta\) from \(H _1\)
Two Tailed Tests
Let \(X_1, X_2, \ldots, X_n\) be a random sample from the normal distribution with mean \(\mu\) and known variance \(\sigma^2\).
Derive a hypothesis test of size \(\alpha\) for testing
We will look at the sample mean \(\bar{X} \ldots\) \(\ldots\) and reject if it is either too high or too low.
Step One
Choose an estimator for μ.
Step Two
Choose a test statistic or Give the “form” of the test.
Reject \(H _0\), in favor of \(H _1\) if either \(\overline{ X }< c\) or \(\bar{X}>d\) for some \(c\) and \(d\) to be determined.
Easier to make it symmetric! Reject \(H _0\), in favor of \(H _1\) if either
for some \(c\) to be determined.
Step Three
Find c.
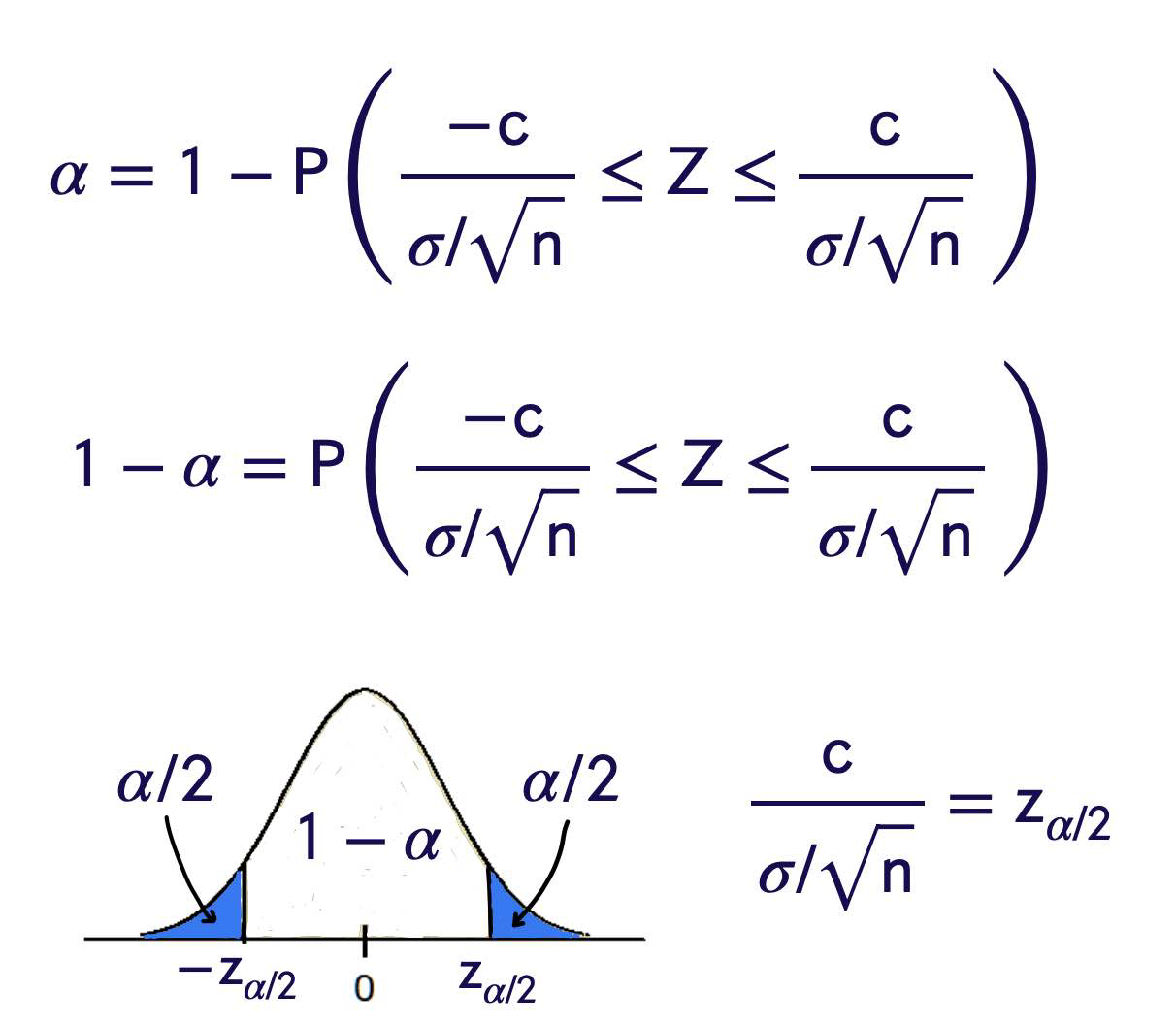
Step Four
Conclusion
Reject \(H _0\), in favor of \(H _1\), if
Example
In 2019, the average health care annual premium for a family of 4 in the United States, was reported to be \(\$ 6,015\).
In a more recent survey, 100 randomly sampled families of 4 reported an average annual health care premium of \(\$ 6,177\). Can we say that the true average, for all families of 4 , is currently different than the sample mean from 2019? $\( \sigma=814 \quad \text { Use } \alpha=0.05 \)$
Assume that annual health care premiums are normally distributed with a standard deviation of \(\$ 814\). Let \(\mu\) be the true average for all families of 4. Hypotheses:
We reject \(H _0\), in favor of \(H _1\). The data suggests that the true current average, for all families of 4 , is different than it was in 2019.

Hypothesis Tests for Proportions
A random sample of 500 people in a certain country which is about to have a national election were asked whether they preferred “Candidate A” or “Candidate B”. From this sample, 320 people responded that they preferred Candidate A.
Let \(p\) be the true proportion of the people in the country who prefer Candidate A.
Test the hypotheses \(H _0: p \leq 0.65\) versus \(H _1: p>0.65\) Use level of significance \(0.10\). We have an estimate
The Model
Take a random sample of size \(n\). Record \(X_1, X_2, \ldots, X_n\) where \(X_i= \begin{cases}1 & \text { person i likes Candidate A } \\ 0 & \text { person i likes Candidate B }\end{cases}\) Then \(X_1, X_2, \ldots, X_n\) is a random sample from the Bernoulli distribution with parameter \(p\).
Note that, with these 1’s and 0’s, $\( \begin{aligned} \hat{p} &=\frac{\# \text { in the sample who like A }}{\# \text { in the sample }} \\ &=\frac{\sum_{ i =1}^{ n } X _{ i }}{ n }=\overline{ X } \end{aligned} \)\( By the Central Limit Theorem, \)\hat{p}=\overline{ X }$ has, for large samples, an approximately normal distribution.
So, \(\quad \hat{p} \stackrel{\text { approx }}{\sim} N\left(p, \frac{p(1-p)}{n}\right)\)
In particular, $\( \frac{\hat{p}-p}{\sqrt{\frac{p(1-p)}{n}}} \)\( behaves roughly like a \)N(0,1)\( as \)n$ gets large.
\(n >30\) is a rule of thumb to apply to all distributions, but we can (and should!) do better with specific distributions.
\(\hat{p}\) lives between 0 and 1.
The normal distribution lives between \(-\infty\) and \(\infty\).
However, \(99.7 \%\) of the area under a \(N(0,1)\) curve lies between \(-3\) and 3 ,
Go forward using normality if the interval $\( \left(\hat{p}-3 \sqrt{\frac{\hat{p}(1-\hat{p})}{n}}, \hat{p}+3 \sqrt{\frac{\hat{p}(1-\hat{p})}{n}}\right) \)\( is completely contained within \)[0,1]$.
Step One
Choose a statistic. \(\widehat{p}=\) sample proportion for Candidate \(A\)
Step Two
Form of the test. Reject \(H _0\), in favor of \(H _1\), if \(\hat{ p }> c\).
Step Three
Use \(\alpha\) to find \(c\) Assume normality of \(\hat{p}\) ? It is a sample mean and \(n>30\).
The interval $\( \left(\hat{p}-3 \sqrt{\frac{\hat{p}(1-\hat{p})}{n}}, \hat{p}+3 \sqrt{\frac{\hat{p}(1-\hat{p})}{n}}\right) \)\( is \)(0.5756,0.7044)$
Reject \(H _0\) if
Formula
T-Tests
What is a t-test, and when do we use it? A t-test is used to compare the means of one or two samples, when the underlying population parameters of those samples (mean and standard deviation) are unknown. Like a z-test, the t-test assumes that the sample follows a normal distribution. In particular, this test is useful for when we have a small sample size, as we can not use the Central Limit Theorem to use a z-test.
There are two kinds of t-tests:
One Sample t-tests
Two Sample t-tests
Let \(X_1, X_2, \ldots, X_n\) be a random sample from the normal distribution with mean \(\mu\) and unknown variance \(\sigma^2\).
Consider testing the simple versus simple hypotheses $\( H _0: \mu=\mu_0 \quad H _1: \mu<\mu_0 \)\( where \)\mu_0$ is fixed and known.
Reject \(H _0\), in favor of \(H _1\), if
unknown!This is a useless test!
It was based on the fact that
What is we use the sample standard deviation \(S =\sqrt{ S ^2}\) in place of \(\sigma\) ?
Thus,
Step four
Conclusion! Reject \(H _0\), in favor of \(H _1\), if
Example
In 2019, the average health care annual premium for a family of 4 in the United States, was reported to be \(\$ 6,015\).
In a more recent survey, 15 randomly sampled families of 4 reported an average annual health care premium of \(\$ 6,033\) and a sample variance of \(\$ 825\).
Can we say that the true average is currently greater than \(\$ 6,015\) for all families of 4 ?
Use \(\alpha=0.10\)
Assume that annual health care premiums are normally distributed. Let \(\mu\) be the true average for all families of 4.
Step Zero
Set up the hypotheses.
Step One
Choose a test statistic
Step Two
Give the form of the test. Reject 𝖧0 , in favor of h1, if 𝟢 𝖧𝟣 𝖷 > 𝖼 where c is to be determined.
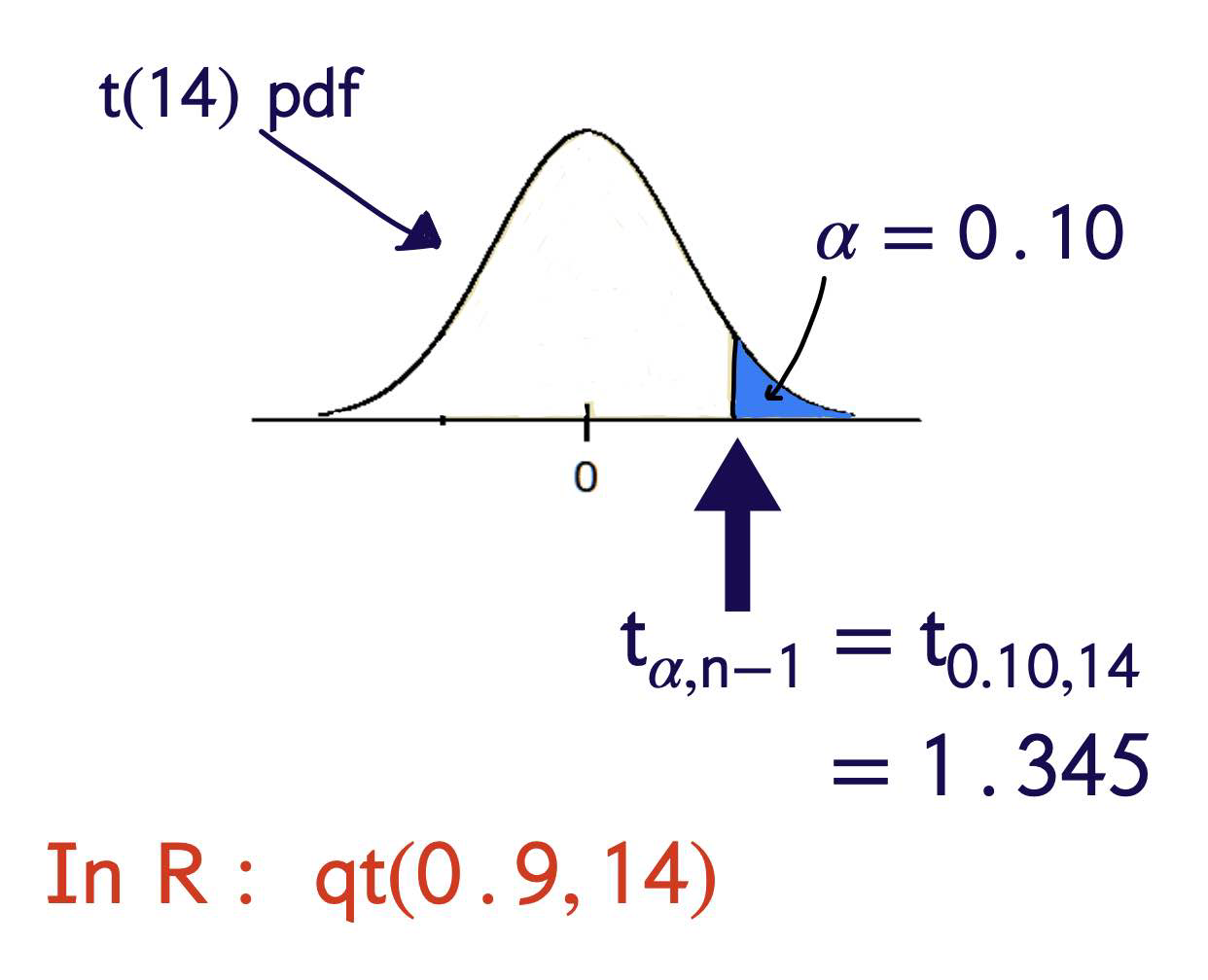
Step Three
Find c
Step Four
Conclusion. Rejection Rule: Reject \(H _0\), in favor of \(H _1\) if
We had \(\bar{x}=6033\) so we reject \(H_0\).
There is sufficient evidence (at level \(0.10\) ) in the data to suggest that the true mean annual healthcare premium cost for a family of 4 is greater than \(\$ 6,015\).
P value
Two Sample Tests for Means
Fifth grade students from two neighboring counties took a placement exam.
Group 1, from County 1, consisted of 57 students. The sample mean score for these students was \(7 7 . 2\) and the true variance is known to be 15.3. Group 2, from County 2, consisted of 63 students and had a sample mean score of \(75.3\) and the true variance is known to be 19.7.
From previous years of data, it is believed that the scores for both counties are normally distributed.
Derive a test to determine whether or not the two population means are the same.
Suppose that \(X _{1,1}, X _{1,2}, \ldots, X _{1, n _1}\) is a random sample of size \(n_1\) from the normal distribution with mean \(\mu_1\) and variance \(\sigma_1^2\). Suppose that \(X_{2,1}, X_{2,2}, \ldots, X_{2, n_2}\) is a random sample of size \(n_2\) from the normal distribution with mean \(\mu_2\) and variance \(\sigma_2^2\).
Suppose that \(\sigma_1^2\) and \(\sigma_2^2\) are known and that the samples are independent.
Think of this as $\( \begin{gathered} \theta=0 \text { versus } \theta \neq 0 \\ \text { for } \\ \theta=\mu_1-\mu_2 \end{gathered} \)$
Step one
Choose an estimator for \(\theta=\mu_1-\mu_2\)
Step Two
Give the “form” of the test. Reject \(H _0\), in favor of \(H _1\) if either \(\hat{\theta}>c\) or \(\hat{\theta}<-c\) for some c to be determined.
Step Three
Find \(c\) using \(\alpha\) Will be working with the random variable
We need to know its distribution…
Step Three
Find c using \(\alpha\).
\(\bar{X}_1-\bar{X}_2\) is normally distributed
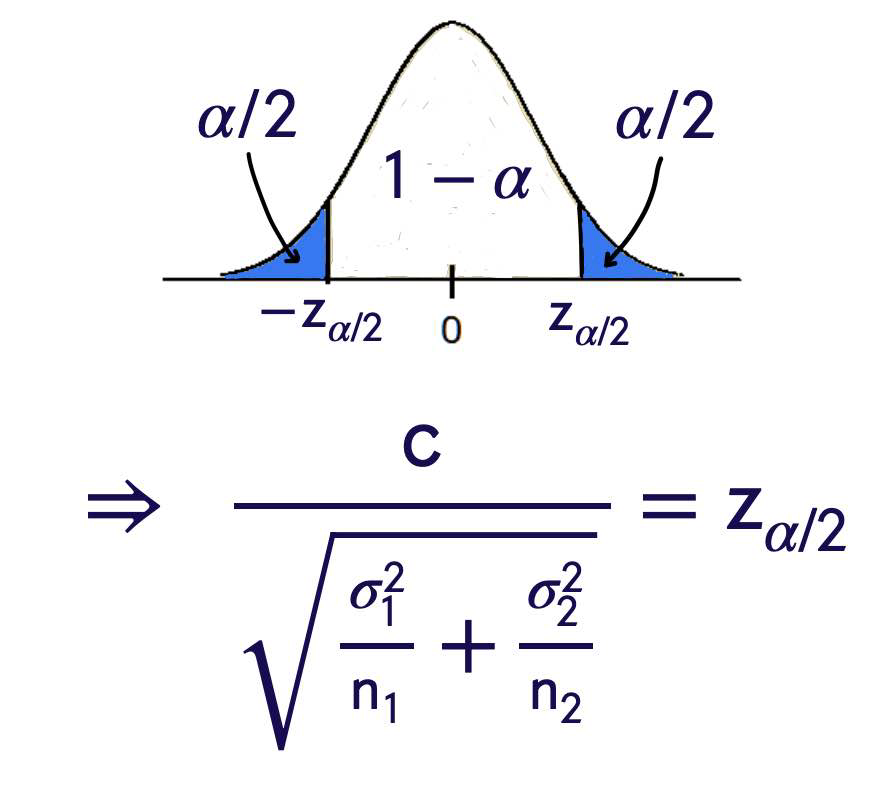
Step Four
Conclusion
Reject \(H _0\), in favor of \(H _1\), if
or
Example
Suppose that \(\alpha=0.05\). $\( \begin{aligned} & z _{\alpha / 2}= z _{0.025}=1.96 \\ & z _{\alpha / 2} \sqrt{\frac{\sigma_1^2}{ n _1}+\frac{\sigma_2^2}{ n _2}}=1.49 \end{aligned} \)$
So,
and we reject \(H _0\). The data suggests that the true mean scores for the counties are different!
Two Sample t-Tests for a Difference of Means
Fifth grade students from two neighboring counties took a placement exam.
Group 1, from County A, consisted of 8 students. The sample mean score for these students was \(77.2\) and the sample variance is \(15.3\).
Group 2, from County B, consisted of 10 students and had a sample mean score of \(75.3\) and the sample variance is 19.7.
Pooled Variance
Step Four
Reject \(H _0\), in favor of \(H _1\), if
or
Since \(\bar{x}_1-\bar{x}_2=1.9\) is not above \(5.840\), or below \(-5.840\) we fail to reject \(H _0\), in favor of \(H _1\) at \(0.01\) level of significance.
The data do not indicate that there is a significant difference between the true mean scores for counties \(A\) and \(B\).
Welch’s Test and Paired Data
Two Populations: Test
Suppose that \(X_{1,1}, X_{1,2}, \ldots, X_{1, n_1}\) is a random sample of size \(n_1\) from the normal
distribution with mean \(\mu_1\) and variance \(\sigma_1^2\).Suppose that \(X_{2,1}, X_{2,2}, \ldots, X_{2, n}\) is a random sample of size \(n_2\) from the normal distribution with mean \(\mu_2\) and variance \(\sigma_2^2\).
Suppose that \(\sigma_1^2\) and \(\sigma_2^2\) are unknown and that the samples are independent. Don’t assume that \(\sigma_1^2\) and \(\sigma_2^2\) are equal!
Welch says that:
has an approximate t-distribution with \(r\) degrees of freedom where
rounded down.

Example
A random sample of 6 students’ grades were recorded for Midterm 1 and Midterm 2. Assuming exam scores are normally distributed, test whether the true (total population of students) average grade on Midterm 2 is greater than Midterm 1. α = 0.05
Student |
Midterm 1 Grade |
Midterm 2 Grade |
|---|---|---|
1 |
72 |
81 |
2 |
93 |
89 |
3 |
85 |
87 |
4 |
77 |
84 |
5 |
91 |
100 |
6 |
84 |
82 |
Student |
Midterm 1 Grade |
Midterm 2 Grade |
Differences: minus 2 Midterm 1 |
|---|---|---|---|
1 |
72 |
81 |
9 |
2 |
93 |
89 |
-4 |
3 |
85 |
87 |
2 |
4 |
77 |
84 |
7 |
5 |
91 |
100. |
9 |
6 |
84 |
82 |
-2 |
The Hypotheses: Let \(\mu\) be the true average difference for all students.
This is simply a one sample t-test on the differences.
Data:
This is simply a one sample t-test on the differences.
This is simply a one sample t-test on the differences.
Reject \(H _0\), in favor of \(H _1\), if
3.5 > 4.6
Conclusion: We fail to reject h0 , in favor of h1 , at 0.05 level of significance.
These data do not indicate that Midterm 2 scores are higher than Midterm 1 scores
Comparing Two Population Proportions
A random sample of 500 people in a certain county which is about to have a national election were asked whether they preferred “Candidate A” or “Candidate B”. From this sample, 320 people responded that they preferred Candidate A.
A random sample of 400 people in a second county which is about to have a national election were asked whether they preferred “Candidate A” or “Candidate B”.
From this second county sample, 268 people responded that they preferred Candidate \(A\).
Test
Change to:
Estimate \(p_1-p_2\) with \(\hat{p}_1-\hat{p}_2\) For large enough samples,
and
Use estimators for p1 and p2 assuming they are the same.
Call the common value p.
Estimate by putting both groups together.
we have
Two-tailed test with z-critical values…
= 0.9397
qnorm(1-0.05/2)
\(Z=-0.9397\) does not fall in the rejection region!
Hypothesis Tests for the Exponential
Suppose that \(X_1, X_2, \ldots, X_n\) is a random sample from the exponential distribution with rate \(\lambda>0\). Derive a hypothesis test of size \(\alpha\) for
What statistic should we use?
Test 1: Using the Sample Mean
Step One
Choose a statistic.
Step Two
Give the form of the test Reject 𝖧0 , in favor of h1 , if 𝖷_bar < 𝖼
for some c to be determined.
Step Three
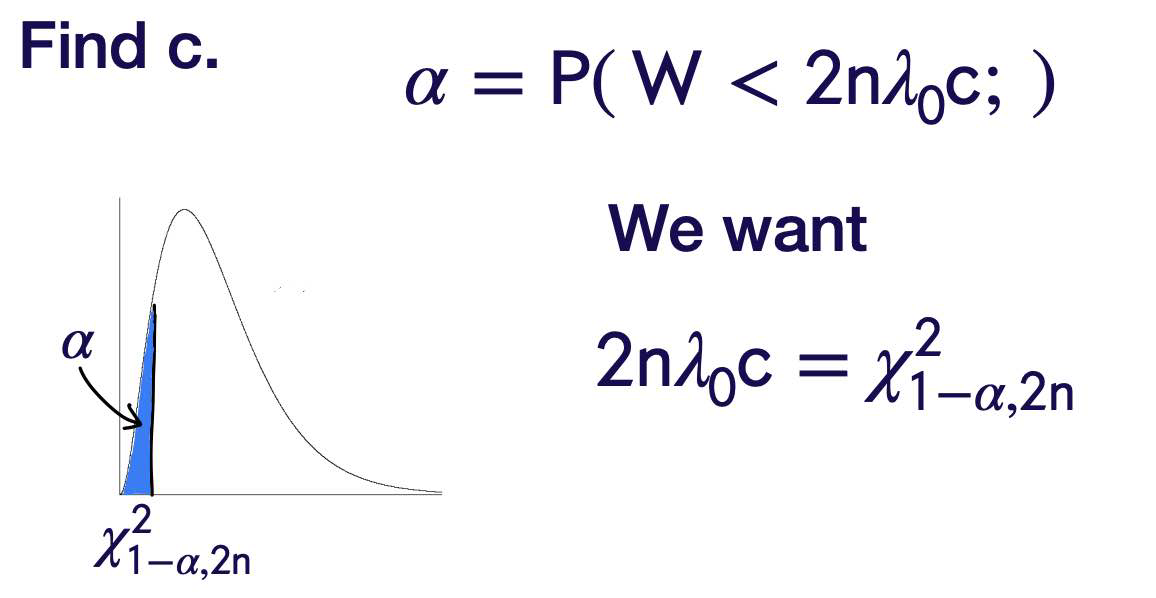
Step Four
Reject \(H _0\), in favor of \(H _1\), if
\(\chi_{\alpha, n }^2\) In R, get \(\chi_{0.10,6}^2\)
by typing qchisq(0.90,6)
Best Test
UMP Tests
Suppose that \(X_1, X_2, \ldots, X_n\) is a random sample from the exponential distribution with rate \(\lambda>0\).
Derive a uniformly most powerful hypothesis test of size \(\alpha\) for
Step One
Consider the simple versus simple hypotheses
for some fixed \(\lambda_1>\lambda_0\).
###Steps Two, Three, and Four
Find the best test of size \(\alpha\) for
for some fixed \(\lambda_1>\lambda_0\). This test is to reject \(H _0\), in favor of \(H _1\) if
Note that this test does not depend on the particular value of \(\lambda_1\). -It does, however, depend on the fact that \(\lambda_1>\lambda_0\)
The “UMP” test for
is to reject \(H_0\), in favor of \(H_1\) if
The “UMP” test for
is to reject \(H_0\), in favor of \(H_1\) if
Test for the Variance of the Normal Distribution
Suppose that \(X_1, X_2, \ldots, X_n\) is a random sample from the normal distribution with mean \(\mu\) and variance \(\sigma^2\). Derive a test of size/level \(\alpha\) for
step 1
Choose a statistic/estimator for \(\sigma^2\)
step 2
Give the form of the test. Reject \(H_0\), in favor of \(H_1\), if
for some \(c\) to be determined.
step 3
find c using alpha
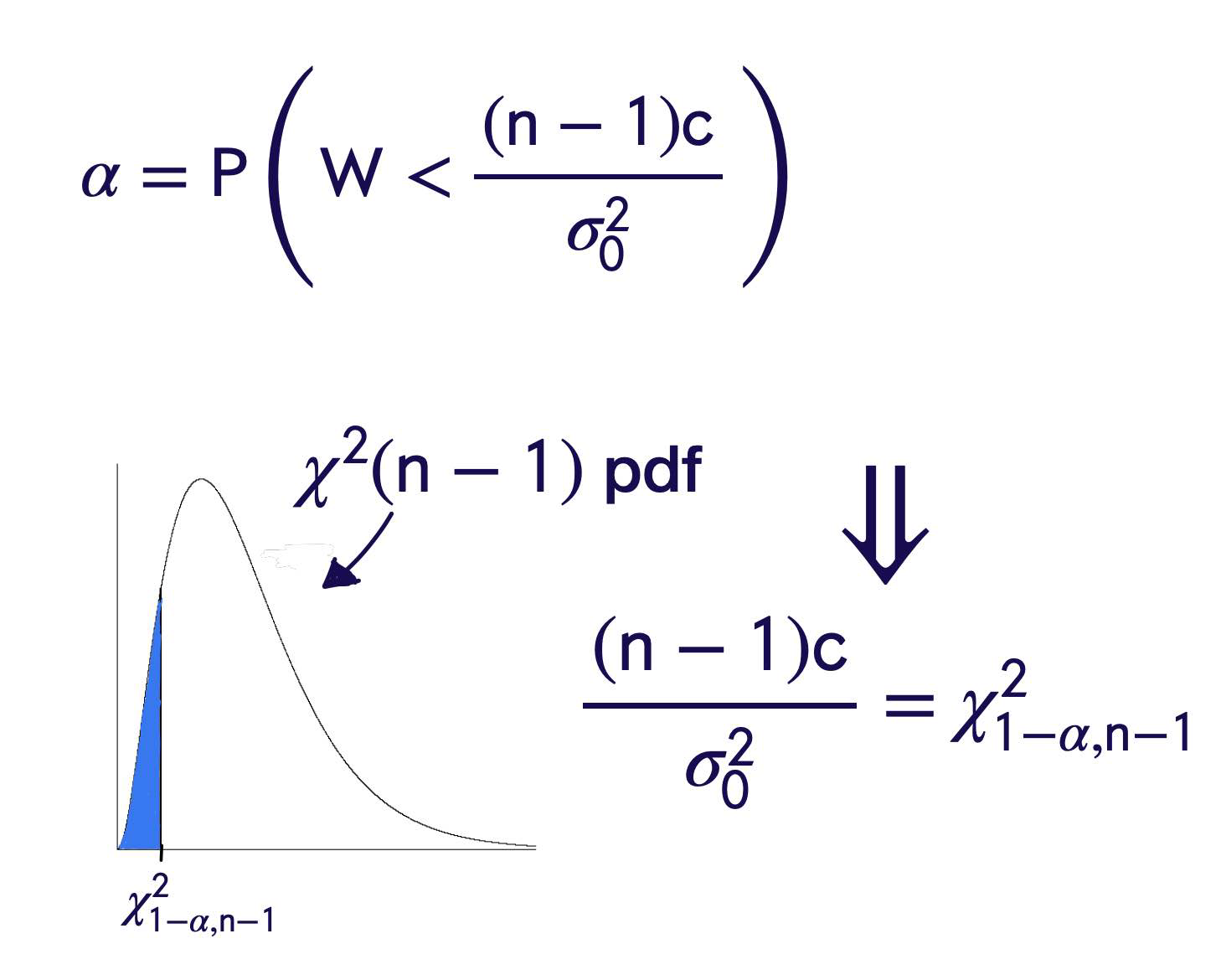
Step 4
Reject \(H _0\), in favor of \(H _1\), if
Example
A lawn care company has developed and wants to patent a new herbicide applicator spray nozzle. Example: For safety reasons, they need to ensure that the application is consistent and not highly variable. The company selected a random sample of 10 nozzles and measured the application rate of the herbicide in gallons per acre
The measurements were recorded as
\(0.213,0.185,0.207,0.163,0.179\)
\(0.161,0.208,0.210,0.188,0.195\)
Assuming that the application rates are normally distributed, test the following hypotheses at level \(0.04\).
Get sample variance in \(R\).
or
Hit
Compute variance by typing
or \(\left(\left(\operatorname{sum}\left(x^{\wedge} 2\right)-\left(\operatorname{sum}(x)^{\wedge} 2\right) / 10\right) / 9\right.\) Result: \(0.000364\)
Reject \(H_0\), in favor of \(H_1\), if \(S^2>c\).
Reject \(H _0\), in favor of \(H _1\), if \(S ^2> c\)
Reject \(H_0\), in favor of \(H_1\), if \(S^2>c\)
Fail to reject \(H _0\), in favor of \(H _1\), at level 0.04. There is not sufficient evidence in the data to suggest that \(\sigma^2>0.01\).